Kooperationspartner Hochschule für Philosohpie, München
Der Lehrstuhl Herrn Prof. Brüntrup und die Comelio GmbH
engagieren sich im Rahmen einer Kooperation für die Entwicklung
einer ontologiebasierten Software-Lösung, welche die Modellierung
einer Ontologie für Frage- und Antwort-Strukturen erfordert. Die
Comelio GmbH erstellt u.a. individuelle Software-Lösungen im
Bereich Business Intelligence oder erweitert Standard-Produkte von
Microsoft und Oracle für Berichts- und Expertensystemen ein. Im
Forschungsprojekt soll versucht werden, eine Daten- und
Softwarestruktur zu entwickeln, mit deren Hilfe konkrete Fragen
und mögliche Antworten zu den allgemein beschriebenen
Frage-/Antwort-Strukturen in der zu Grunde liegenden Ontologie in
Beziehung gesetzt werden. Dies soll dazu führen, dass sich
Fragebögen, Validierungen und Standard-Auswertungen vereinfachen
und teilweise automatisch durchführen lassen.
Der innovative Kern des Vorhabens liegt in der dynamischen und
kontextbezogenen Generierung von Fragebögen und
Auswertungsalgorithmen. Hiefür muss eine übergeordnete Ontologie
gefunden werden, die zusammen mit der Hochschule entwickelt werden
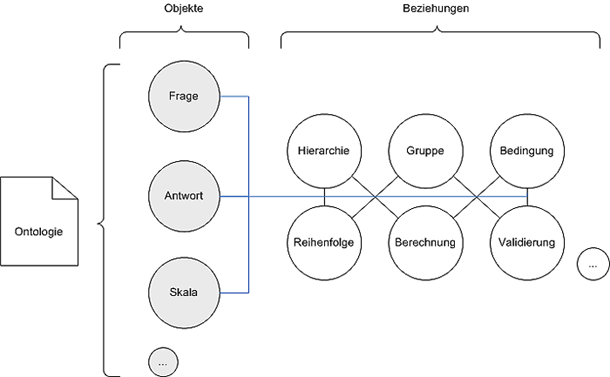
soll. Die Zusammenhänge von Hierarchie, Gruppe, Bedingung usw.
müssen gebildet und erfasst werden. Darüber hinaus werden durch
Comelio mehrere Module entwickelt, die softwaretechnisch
aufeinander abgestimmt werden müssen. Hierzu zählen u.a.: ein
Modul zur automatischen Ableitung von individuellen Befragungen
aus der Datenontologie, ein Auswertungs- und Berichtsmoduls, ein
Bearbeitungs- und Zugriffsmodul.
Der Lehrstuhl von Herrn Prof. Dr. Godehard Brüntrup SJ wird das
Entwicklungsvorhaben der Comelio GmbH wissenschaftlich untersetzen
und begleiten. Seitens der Hochschule sollen die theoretischen und
anwendungsspezifischen Grundlagen geliefert werden, um eine
spätere rechnergestützte Semantik als ein Netz aus Begriffen und
Relationen ermöglichen zu können. Die Hochschule wird sich an
aktuellen, formalen Forschungsmethoden aus den
Sozialwissenschaften und bereits ausgearbeiteten
Softwareontologien orientieren und die notwendigen Grundlagen aus
der einschlägigen Literatur gewinnen. Befragungs- und
Auswertungsontologien sind aber nicht die paradigmatischen
ontologischen Gegenstandsgebiete (Physik, Biologie, Psychologie).
Die innovative Herausforderung des Projekts besteht darin, in
einem Bereich, der ontologisch viel weniger ernstgenommen wurde,
durch die ontologische Methode zwei sehr allgemeine
Kategorienschablonen zu finden, anhand derer generisch Umfragen
erstellt und ausgewertet werden können.
Entscheidend werden darüber hinaus die gemeinsame Konzeption zu
Beginn des Vorhabens, der theoretisch-konzeptionelle Entwurf des
Entwicklungsprozesses für Comelio sowie die abschließende
Untersuchung und Unterstützung der Hochschule bei den
Prototypentests sein. Für die Hochschule für Philosophie ist es
ein Ziel, Forschungen mit umfangreichem Praxisbezug im Bereich der
Schnittstelle zwischen philosophischer Ontologie, Informatik und
Sozialwissenschaften zu intensivieren und diese in entsprechenden
Veröffentlichungen zu artikulieren. Ontologie war von je her eine
Domäne der Philosophie. In den letzten Jahrzehnten wurde sie
systematisch für die Informatik fruchtbar gemacht. Da im
vorliegenden Projekt (Fragen und Auswertungen) zwei Ontologien
benötigt werden, wird eine bestehende Arbeitsgruppe von zwei
post-graduierten Studenten mit besonderen Qualifikationen im
Bereich formaler Sprachen und mathematischer Logik in
Zusammenarbeit mit Prof. Brüntrup das Projekt leiten und
durchführen. Von daher ergibt sich die im Antrag ausgewiesene
Notwendigkeit von zwei halben Stellen. Um sich in der
anspruchsvollen Fragestellung des Projekts auf einen
weitestmöglichen Pool von Denkansätzen stützen zu können, wird ein
Hauptseminar an der Hochschule für Philosophie mit Studenten
verschiedenster Fachrichtungen den Zusammenhang von allgemeiner
Ontologie und Informatik zum Thema haben. Es ist zu erwarten, dass
dabei ambitionierte Essays entstehen, die konkrete Problemlösungen
zu speziellen Umfrageontologien entwerfen und genau analysieren.
Sollten diese Entwürfe für das Entwicklungsprojekt von Comelio
praxisrelevant werden, ist auch im Kontext des Seminars mit einer
Veröffentlichung zu rechnen. Insbesondere dann, wenn ein solcher
Essay in eine ausführliche, projektrelevante Abschlussarbeit
ausgeweitet wird.
Projektplan
Vorgehen
Entwicklungsvorbereitung
Zu Beginn des Vorhabens muss das Projekt exakt durchgeplant und
dessen Teilstücke aufeinander abgestimmt werden. In diesem
Zusammenhang ist vor allem die Zusammenarbeit und der genaue
zeitliche Rahmen mit der Hochschule zu präzisieren, da die
Arbeiten von Comelio darauf aufbauen.
Am Ende des ersten Arbeitspaketes soll in einem Feinkonzept ein
präzis herausgearbeiteter Arbeitsplan stehen und die technischen
Entwicklungsbereiche klar definiert und abgegrenzt sein.
Analyse verwertbarer Standards zu Ontologien und Schnittstellen
Im Rahmen des zweiten Arbeitspakets werden die am Markt frei
verfügbaren Lösungen und Konzepte zu Ontologien auf eine mögliche
Verwendung innerhalb dieses Entwicklungsvorhabens untersucht und
bewertet. Im weiteren sollen auch mögliche – bzw. notwendige –
Schnittstellen für die geplante Entwicklung evaluiert werden. Dies
ist notwendig um einerseits einen möglichst breite Aufstellung –
und damit eine hohe Marktakzeptanz – der geplanten Entwicklung zu
erreichen, andererseits sollen spätere kostenintensive
Lizenzzahlungen vermieden werden.
Darüber hinaus soll im Rahmen dieses Entwicklungsvorhabens
zusammen mit der Hochschule evaluiert werden, wie sich die zu
entwickelnden Ontologien programmatisch bestmöglich umsetzen und
in die Regelmaschine einbinden lassen.
Konzept zur dynamischen und kontextbezogen
Zusammenhangserkennung zwischen Fakten
Im dritten Arbeitspaket sollen die Grundlagen für die dynamische
kontextsemantische Verknüpfung zwischen den einzelnen
Informationen gelegt werden. Die Grundlage bildet ein vom
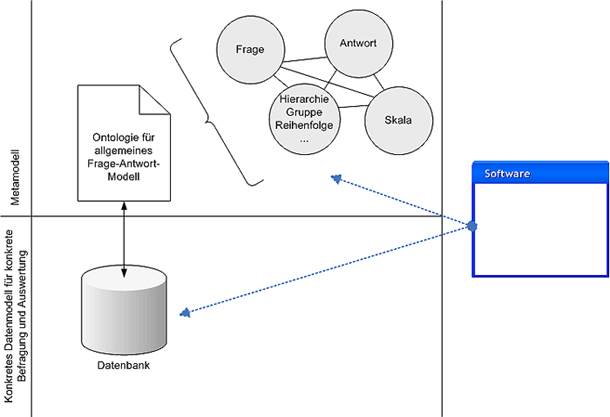
Hochschul-Partner zu entwickelndes Datenmodell für die Frage- und
Antwortstrukturen, das von Comelio umfassend weiterentwickelt
wird.
Dazu müssen die sich ableitenden Beziehungszusammenhänge zwischen
Hierarchie, Gruppe, Bedingung, Datenzugriff und Stammdaten erfasst
und gespeichert werden. Die darüber gewonnenen Informationen
bilden wiederum die Basis für die Verwendung für künftige
Befragungen.
Ziel der Konzeption ist ein System, mit dessen Hilfe einzelne
Befragungen sich iterativ verbessern, indem irrelevante Daten und
Pfade ausselektiert und zielführende Zusammenhänge besonders
berücksichtigt werden.
In diesem Zusammenhang sind Fragestellungen zur
Strukturierung/Aufbau/Anzeige der Fragebögen sowie der
Flusskontrolle und der Angabenvalidierung in dem Konzept zu
berücksichtigen.
Entwicklung einer Datenontologie für eine Regelmaschine
Die Entwicklung der eigentlichen Struktur für eine Datenontologie
für die zu entwickelnde Regelmaschine ist höchst anspruchsvoll und
stellt ein zentrales Entwicklungspaket in diesem Vorhaben dar. Aus
diesem Grunde ist dies in mehrere Teilpakete unterteilt.
Einsatz von Semantischen Technologien
Modellierung der Ontologien
Basierend auf den ersten Ergebnissen der wissenschaftlichen
Forschungen der Hochschule soll im ersten Unterpunkt ein
Grundmodell für eine geeignete Datenontologie entwickelt werden.
Dies ist nach derzeitigem Erkenntnisstand herausfordernd, da die
zu entwickelnde Ontologie speziell auf den Anwendungsfall der
Fragebogengenerierung und Datenerhebung zuge-schnitten werden
soll. Inhaltlich muss die Ontologie jedoch selbst mit jedem
beliebigen Interviewthema befüllt und bearbeitet werden können.
Dies bedeutet, dass die Strukturen einerseits weitgehend flexibel,
andererseits jedoch nicht zu komplex gestaltet werden dürfen, um
etwaige Performanceprobleme bereits auf konzeptioneller Ebene zu
vermeiden.
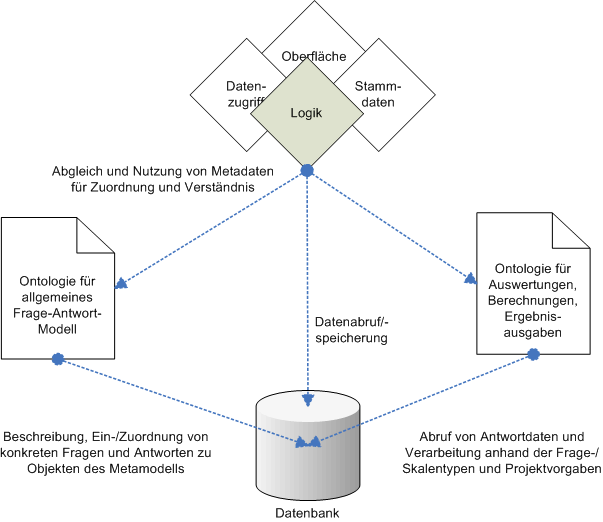
Konzept zur Verknüpfung der Ontologien
Im Rahmen des Arbeitspaketes soll ein geeignetes,
leistungsfähiges Mapping (Verknüpfung) zwischen der Ontologie für
das allgemeine Frage-Antwort-Modell und der Ontologie für die
Auswertung und Berechnungen/Ergebnisausgabe entwickelt werden.
Dazu ist eine Methodik zu entwickeln und umzusetzen, die den
Austausch von strukturierten Daten zwischen den beiden Ontologien
ermöglicht.
Der Realisierung voraus geht dabei eine Evaluierung möglicher
Abfragesprachen bzw. Transformationsmethoden. So sind nach
derzeitigem Erkenntnisstand beispielsweise XPath und Xlink
mögliche Ansatzpunkte für ein geeignetes Mapping.
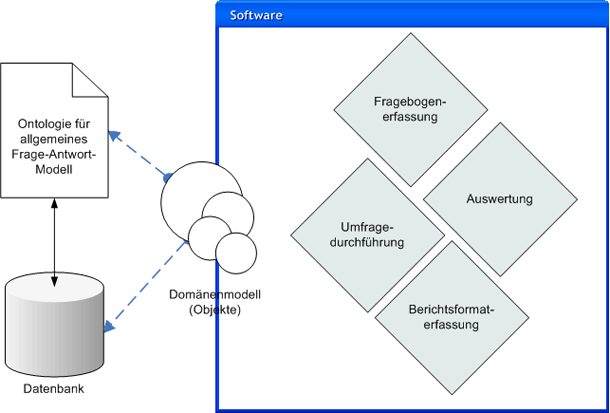
Entwicklung eines Moduls zur automatischen Ableitung von
individuellen Befragungen aus der Datenontologie
Aufbauend auf den Ergebnissen aus dem Arbeitspaket zur
Entwicklung einer geeigneten Ontologie-Struktur soll in diesem
Schritt ein Modul entwickelt werden, das einen automatischen
Abgleich von Metadaten als Basis der semantischen Zuordnung der
vorhandenen Informationen in einem allgemeinen
Frage-Antwort-Modell gestattet. Dies gestaltet sich aller
Voraussicht nach hoch anspruchsvoll, da dieses Modul die
technologische Grundlage für eine kontinuierliche Verbesserung der
Auswertungsverfahren durch ein automatisches Erkennen irrelevanter
Informationen darstellt.
Im weiteren sollen die Erkenntnisse aus dem zweiten Arbeitspaket
aufgegriffen und als ein Fundament für die Entwicklung eines
dynamischen Regelsystems genutzt werden. Motivation und Anspruch
sind dabei eine hohe Dynamisierung bei der Erstellung und
Zuordnung der Fragen bei der Datenerhebung sowie bei der
Verarbeitung und Auswertung der gewonnenen Daten.
Die Erkenntnisse der Hochschule aus dem Arbeitspaket zur
Entwicklung einer innovativen Befragungsmethodik für ein
ontologiebasiertes Befragungssystem werden hier durch Comelio
softwaretechnisch umgesetzt.
Entwicklung eines Bearbeitungs- und Zugriffsmoduls für die
Datenontologie
Aufbauend auf den Ergebnissen der vorangegangenen Arbeitspakete
soll ein Modul entwickelt werden, das einen Zugriff und eine
Bearbeitung der zugrundliegenden Datenontologie erlaubt. In diesem
Zusammenhang sind Werkzeuge zu entwickeln, die auch einem weniger
geübten Anwender eine Modellierung und Anpassung von geeigneten,
anwendungsfallspezifischen Ontologien und Regeln gestatten.
Anspruchsvoll und neuartig ist dieser Aspekt, da die zu
realisierenden Werkzeuge speziell auf den Anwendungsbereich der
Datenerhebung und Auswertung der Fragebögen zugeschnitten werden
sollen.
Entwicklung eines Konzeptes zur persistenten Datenvorhaltung
Im Rahmen des fünften Arbeitspaketes soll ein Konzept für das
Programmmodul entwickelt werden, das eine dauerhafte und
unveränderbare Datenerhebung über eine zu entwickelnde
Datenschnittstelle gestattet. Die Umsetzung der Datenverwaltung
soll es ermöglichen, dass die genutzte Datenquelle ausgetauscht
werden kann, ohne umfangreiche änderungen an Programm-Interna
vorzunehmen. Das Modul bietet somit Schnittstellen für den
Datenimport und -export sowie zur Datensicherung über verschiedene
Medien.
Eine dauerhafte, nicht-flüchtige Datenspeicherung ist notwendig,
um eine nachträgliche Nachvollziehbarkeit der Datenerhebung zu
gewährleisten. Dies ist vor allem unter Beachtung der
automatisierten Relevanz-Erfassung und Gewichtung erforderlich, um
eventuelle Interpretationsspielräume aufzuspüren, kontrollieren
bzw. einzugrenzen.
Entwicklung eines neuartigen ontologiebasierten Auswertungs- und
Berichtsmoduls
Basierend auf den Ergebnissen der Forschungsleistungen des
Hochschulpartners soll in diesem Arbeitspaket ein innovatives
Datenauswertungs- und Berichtsmodul entwickelt werden. Durch
dieses Modul soll ein Anwender später in der Lage sein,
ontologisch verknüpfte Er-gebnisse aus einer Datenerhebung
aufzubereiten und zu analysieren.
Bei der Komponente für die Berichtserfassung ist es das Ziel,
Reihenfolgen von verwerteten Fragegruppen zu erfassen und dann
über einzelne Themenbereiche Berichte auszugeben. Dabei soll das
Modul so umgesetzt werden, dass beliebige – bzw. beliebig komplexe
– Auswertungstechniken in der geplanten Entwicklung realisiert
werden können.
Für den Test über die Mächtigkeit des Moduls und einer
ordnungsgemäßen Funktionsweise sollen im Rahmen dieses
Arbeitspaketes auch einige Standardauswertungstechniken und
Diagramme umgesetzt werden.
Entwicklung und programmatische Umsetzung von Schnittstellen
Basierend auf den gewonnenen Ergebnissen aus dem vorangegangenen
Arbeitspaket sowie den Resultaten des zweiten Arbeitspaketes
müssen die elementare Schnittstellenmodule programmatisch
umgesetzt werden.
Anspruchsvoll ist dieses Arbeitspaket, da bei einem zu erwartenden
hohen Datenaufkommen aus Datenerhebungen Konsistenzprüfungen
durchzuführen sind. Gleichzeitig muss das Programm jedoch auch
genügend leistungsstark sein, um die Daten innerhalb eines
angemessenen Zeitraums verarbeiten zu können. Diese
Konsistenzprüfungen sollen dabei automatisiert durch die zu
entwickelnde Regelmaschine geleistet werden.
Im weiteren muss für eine optimale kontextsemantische Verarbeitung
beim Import von konventionellen Datenerhebungen dem Anwender die
Möglichkeit gegeben werden, die zu importierenden Daten mit
zusätzlichen Metadaten zu versehen. Zugleich müssen jedoch über
eine leistungsstarke Verlaufsfunktion änderungen an der Datenbasis
erfasst werden, um mögliche Manipulationen an den Fakten zu
vermeiden.
Entwicklung eines Konzeptes zur Zusammenarbeit aller zu
entwickelnder Module
In den vorangegangen Entwicklungsschritten sind die einzelnen
Komponenten getrennt voneinander entwickelt worden. Im Rahmen des
achten Arbeitspaketes soll nun ein Konzept entwickelt werden, das
eine Zusammenarbeit zwischen den einzelnen Programmmodulen
ermöglicht.
Comelio strebt dabei an, dieses Konzept möglichst modular, offen
und universell zu gestalten, damit eine mögliche Erweiterung und
Anpassung des Gesamtsystems bzw. der problemlose Austausch
einzelner Programmteile ohne großen Aufwand möglich ist.
Nach derzeitigem Erkenntnisstand erweist sich diese modulare
Grundkonzeption als anspruchsvoll, da die Regeln und Ontologien
als zentrale Bestandteile des Gesamtsystems derart flexibel
umgesetzt werden sollen, dass diese mit beliebigen und (nahezu)
unbegrenzt umfangreichen Inhalten befüllt werden sollen.
Gleichzeitig muss die Regelmaschine die Daten genügend schnell und
ressourcenschonend verarbeiten können.
Programmatische Umsetzung eines Prototypen
Im Rahmen dieses Arbeitspaketes sollen die entwickelten Konzepte
und Module zu einem leistungsfähigen Gesamtsystem kombiniert und
integriert werden. Bereits an dieser Stelle auftretende
konzeptionelle Defizite in der Regelmaschine sollen – sofern
möglich – bereits frühzeitig angegangen und korrigiert werden.

 In der nachstehenden Liste sind weitere angestrebte technische
Parameter zusammengefasst, die in dem angedachten
Entwicklungsvorhaben erreicht werden sollen.
In der nachstehenden Liste sind weitere angestrebte technische
Parameter zusammengefasst, die in dem angedachten
Entwicklungsvorhaben erreicht werden sollen.