Data Mining mit R
R ist eines der leistungsfähigsten Werkzeuge für statistisches Lernen und Data Mining. Die Sprache bietet eine enorme Bandbreite spezialisierter Algorithmen, modernste Machine-Learning-Bibliotheken und ein ausgereiftes Ökosystem für explorative Analysen, Modellierung und Visualisierung.
Mit R lassen sich komplexe Muster erkennen, Prognosen entwickeln und datenbasierte Entscheidungen unterstützen – ideal für Fachbereiche wie Risikoanalyse, Kundenmanagement, Qualitätssicherung oder Betrugserkennung.
R überzeugt insbesondere in Projekten, in denen statistische Methoden, erklärbare Modelle und flexible Auswertungen im Vordergrund stehen. Durch seine offenen Standards eignet es sich gleichermaßen für Forschung, Banken und Versicherungen, Handel sowie technische Anwendungsbereiche.

Data-Mining-Methoden in R
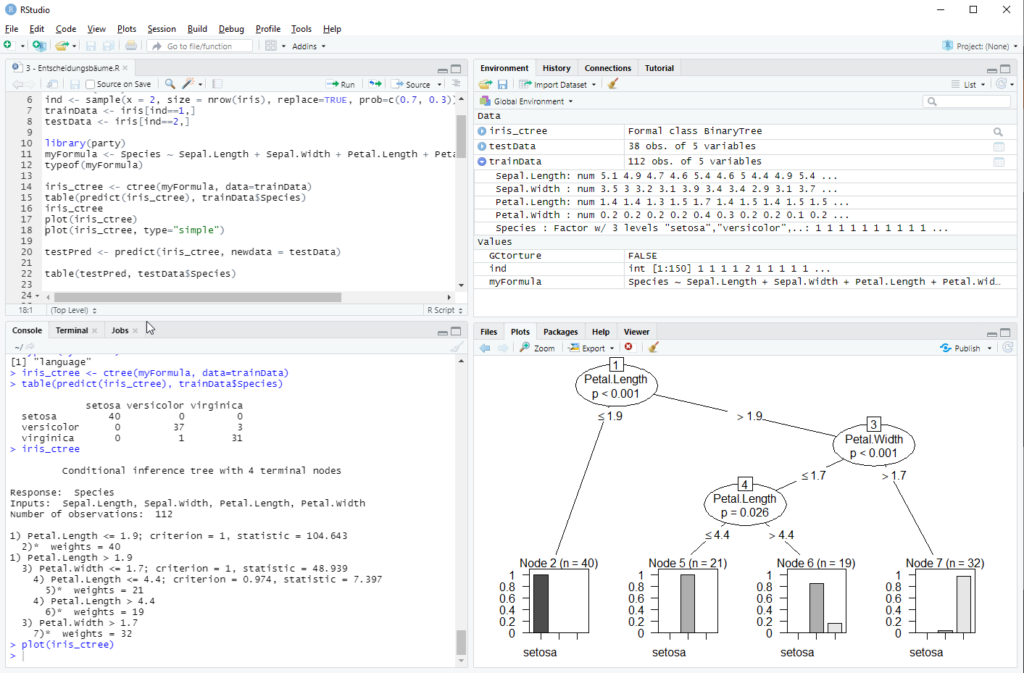
R bietet ein sehr breites Portfolio an Algorithmen – von klassischen statistischen Verfahren bis hin zu modernen Machine-Learning-Methoden. Dazu gehören unter anderem:
Vorverarbeitung & Explorative Analyse
- Data Cleaning, fehlende Werte, Outlier Detection
- Feature Engineering und Feature Selection
- Explorative Statistik und Visualisierung (ggplot2, lattice)
Überwachte Lernverfahren
- Lineare und logistische Regression
- Random Forests und Entscheidungsbäume (rpart, ranger)
- Gradient Boosting (xgboost, LightGBM via R-Paket)
- Support Vector Machines (kernlab)
- Künstliche neuronale Netze (keras, nnet)
Unüberwachtes Lernen
- Clusterverfahren (k-Means, Hierarchical Clustering, DBSCAN)
- Principal Component Analysis (PCA)
- Anomaly Detection
- Market Basket Analysis (arules, Apriori)
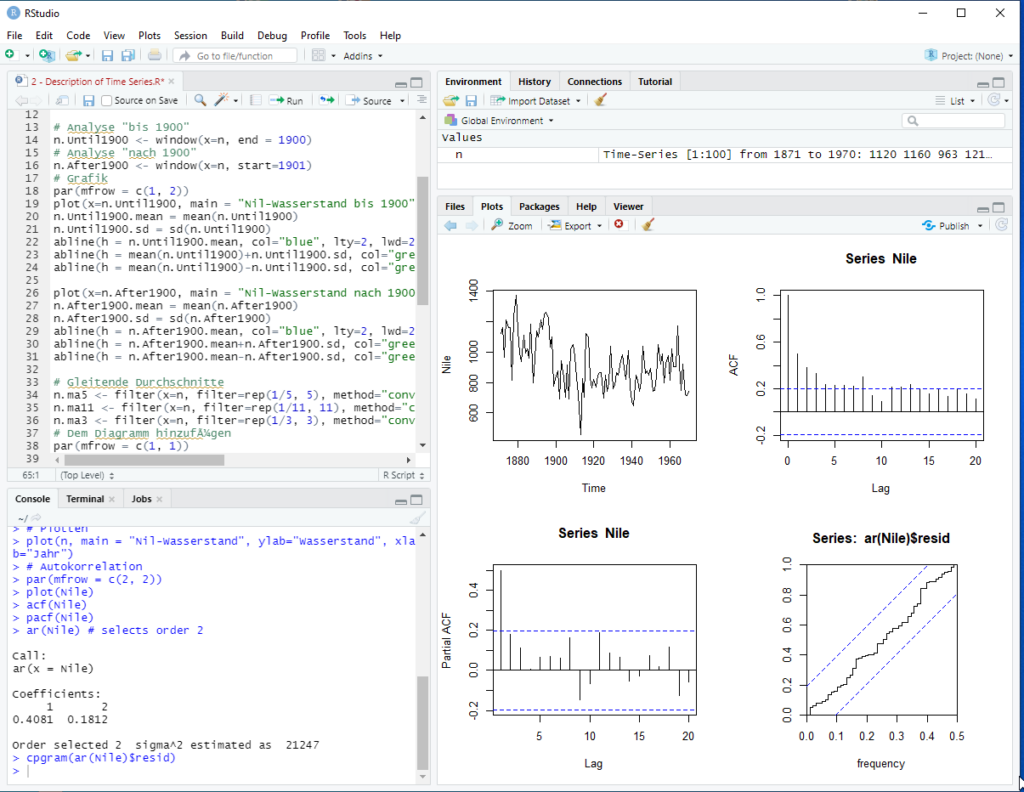
Zeitreihenanalyse
- ARIMA / SARIMA, Prophet, Exponentielle Glättung
- Forecasting für KPIs, Nachfrage, Risiken oder Volumina
Text Mining & Natural Language Processing
- Sentiment-Analyse
- Tokenisierung, Stemming, Lemmatisierung
- Topic Models (LDA)
Aufbau von Data-Mining-Lösungen in R

Data-Mining-Anwendungen in R folgen typischerweise einem strukturierten Workflow:
Datenanbindung & Integration
- Import aus SQL Server, Oracle, CSV, XML, JSON oder APIs
- Verbindung zu modernen Plattformen (Microsoft Fabric, Databricks, Lakehouse)
Datenaufbereitung & Feature Engineering
- Transformationen, Bereinigung, Encoding
- Erstellen neuer Variablen und Merkmalssets
Modellerstellung & Training
- Training und Validierung mit Cross-Validation
- Hyperparameteroptimierung
- Vergleich alternativer Modellklassen
Deployment & Operationalisierung
- R Markdown Reports
- Shiny Web-Applikationen
- Integration in Python-, SQL- oder Fabric-Workflows
- Automatisierte Modellläufe
Services
Wir unterstützen Unternehmen in allen Phasen eines Data-Mining-Projekts – von der ersten Analyse bis zum produktiven Betrieb.
Analyse & Beratung
- Machbarkeitsanalysen und Identifikation Use Cases
- Auswahl geeigneter Algorithmen und Modellierungsstrategien
- Bewertung von Datenquellen und Qualität
Modellentwicklung
- Entwicklung überwachter und unüberwachter Modelle
- Forecasting-Modelle und KPI-Prognosen
- Risiko-, Churn-, Fraud- oder Qualitätsmodelle
Implementierung & Integration
- Einbettung in bestehende Analytics- oder BI-Infrastrukturen
- Nutzung von R in Microsoft Fabric (SparkR, R-Notebooks)
- Integration in Oracle mittels Oracle R Enterprise
- Erstellung von Shiny-Anwendungen für interaktive Analysen
Schulung & Wissensaufbau
- Data Mining mit R – Grund- und Aufbaukurse
- Workshops für Shiny, ggplot2, tidymodels
- Coaching für interne Teams & Data Scientists